Wat zijn karaktercoderingen zoals ANSI en Unicode en hoe verschillen ze?
ASCII, UTF-8, ISO-8859 ... Misschien heb je deze vreemde monikers wel eens zien rondzweven, maar wat ze eigenlijk? Lees verder als we uitleggen wat karaktercodering is en hoe deze acroniemen betrekking hebben op de platte tekst die we op het scherm zien.
Fundamentele bouwstenen
Als we het hebben over geschreven taal, praten we over letters als de bouwstenen van woorden, die vervolgens zinnen, alinea's, enzovoort maken. Letters zijn symbolen die geluiden voorstellen. Wanneer je over taal spreekt, heb je het over groepen geluiden die samenkomen om een soort van betekenis te vormen. Elk taalsysteem heeft een complexe set regels en definities die deze betekenissen bepalen. Als je een woord hebt, is het nutteloos tenzij je weet uit welke taal het afkomstig is en je het gebruikt met anderen die die taal spreken.

(Vergelijking van Grantha, Tulu en Malayalam scripts, Afbeelding van Wikipedia)
In de wereld van computers gebruiken we de term 'karakter'. Een karakter is een soort abstract begrip, gedefinieerd door specifieke parameters, maar het is de fundamentele eenheid van betekenis. Het Latijnse 'A' is niet hetzelfde als een Grieks 'alpha' of een Arabisch 'alif' omdat ze verschillende contexten hebben - ze zijn van verschillende talen en hebben iets andere uitspraken - dus we kunnen zeggen dat het andere karakters zijn. De visuele weergave van een teken wordt een "glyph" genoemd en verschillende sets glyphs worden lettertypen genoemd. Groepen tekens behoren tot een 'set' of een 'repertoire'.
Wanneer u een alinea typt en u het lettertype wijzigt, verandert u niet de fonetische waarden van de letters, maar verandert u hoe ze eruitzien. Het is gewoon cosmetisch (maar niet onbelangrijk!). Sommige talen, zoals oude Egyptische en Chinese, hebben ideogrammen; deze vertegenwoordigen hele ideeën in plaats van geluiden, en hun uitspraken kunnen variëren in de tijd en de afstand. Als je het ene personage vervangt door het andere, vervang je een idee. Het is meer dan alleen het veranderen van letters, het is het veranderen van een ideogram.
Tekencodering

(Afbeelding van Wikipedia)
Wanneer u iets op het toetsenbord typt of een bestand laadt, hoe weet de computer wat moet worden weergegeven? Dat is waar karaktercodering voor is. Tekst op uw computer is niet echt een letter, het is een reeks van gepaarde alfanumerieke waarden. De tekencodering fungeert als een sleutel waarvoor waarden overeenkomen met welke tekens, net zoals de manier waarop orthografie dicteert welke geluiden overeenkomen met welke letters. Morsecode is een soort van tekencodering. Het legt uit hoe groepen lange en korte eenheden, zoals piepjes, tekens vertegenwoordigen. In Morse-code zijn de tekens alleen Engelse letters, cijfers en volledige registers. Er zijn veel coderingen van computerkarakters die worden vertaald in letters, cijfers, accenttekens, leestekens, internationale symbolen, enzovoort.
Vaak wordt over dit onderwerp ook de term 'codetabellen' gebruikt. Het zijn in wezen karakter coderingen zoals gebruikt door specifieke bedrijven, vaak met kleine aanpassingen. De Windows 1252-codepagina (voorheen bekend als ANSI 1252) is bijvoorbeeld een gewijzigde vorm van de ISO-8859-1. Ze worden meestal gebruikt als een intern systeem om te verwijzen naar standaard en gemodificeerde karaktercoderingen die specifiek zijn voor dezelfde systemen. Vroeger was karaktercodering niet zo belangrijk omdat computers niet met elkaar communiceerden. Nu internet steeds populairder wordt en netwerken veel voorkomt, is het een steeds belangrijker onderdeel van ons dagelijks leven geworden zonder dat we het ons realiseren.
Many Different Types
(Image from sarah sosiak)
Er zijn veel verschillende karaktercoderingen die er zijn, en daar zijn tal van redenen voor. Welke tekencodering je kiest, hangt af van wat je nodig hebt. Als u in het Russisch communiceert, is het logisch om een tekencodering te gebruiken die goed is voor Cyrillic. Als je in het Koreaans communiceert, wil je iets dat goed is voor Hangul en Hanja. Als u een wiskundige bent, wilt u iets dat alle wetenschappelijke en wiskundige symbolen goed vertegenwoordigd heeft, evenals de Griekse en Latijnse glyphs. Als je een grappenmaker bent, kun je misschien profiteren van omgekeerde tekst. En als u wilt dat al deze soorten documenten door een bepaalde persoon worden bekeken, wilt u een codering die vrij algemeen en gemakkelijk toegankelijk is.
Laten we een paar van de meer algemene bekijken.

(Fragment van ASCII-tabel, afbeelding van asciitable.com)
- ASCII - De Amerikaanse standaardcode voor informatie-uitwisseling is een van de oudere karaktercoderingen. Het was oorspronkelijk bedacht op basis van telegrafische codes en evolueerde in de loop van de tijd om meer symbolen en sommige nu-verouderde niet-afgedrukte besturingspersonages op te nemen. Het is waarschijnlijk zo eenvoudig als je kunt krijgen in termen van moderne systemen, omdat het beperkt is tot het Latijnse alfabet zonder geaccentueerde karakters. De 7-bits codering kan slechts 128 tekens bevatten, vandaar dat er wereldwijd verschillende niet-officiële varianten worden gebruikt.
- ISO-8859 - De meest gebruikte groep karaktercoderingen van de International Organization for Standardization is nummer 8859 Elke specifieke codering wordt aangeduid met een nummer, vaak voorafgegaan door een beschrijvende naam, bijvoorbeeld ISO-8859-3 (Latijns-3), ISO-8859-6 (Latijns / Arabisch). Het is een superset van ASCII, wat betekent dat de eerste 128 waarden in de codering hetzelfde zijn als ASCII. Het is echter 8-bits en biedt ruimte voor 256 tekens, dus het bouwt vanaf daar af en bevat een veel breder scala aan tekens, waarbij elke specifieke codering is gericht op een andere reeks criteria. Latin-1 bevatte een aantal letters en symbolen met accenten, maar werd later vervangen door een herziene set met de naam Latin-9, inclusief bijgewerkte glyphs zoals het eurosymbool.
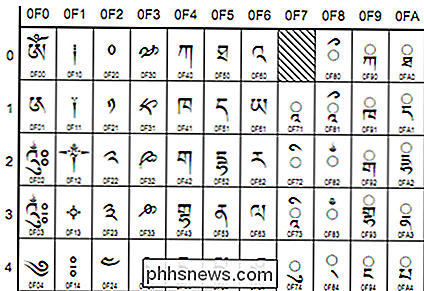
(Fragment van het Tibetaanse schrift Unicode v4, van unicode.org)
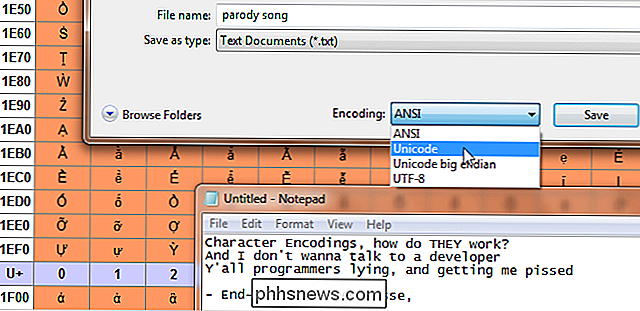
- Unicode - Deze coderingsnorm streeft naar universaliteit. Het bevat momenteel 93 scripts die in verschillende blokken zijn georganiseerd, met nog veel meer in de maak. Unicode werkt anders dan andere tekensets doordat in plaats van direct te coderen voor een glyph, elke waarde verder wordt doorgestuurd naar een 'codepunt'. Dit zijn hexadecimale waarden die overeenkomen met tekens, maar de glyphs zelf worden op een vrijstaande manier door het programma verstrekt , zoals uw webbrowser. Deze codepunten worden gewoonlijk als volgt weergegeven: U + 0040 (wat zich vertaalt naar '@'). Specifieke coderingen volgens de Unicode-standaard zijn UTF-8 en UTF-16. UTF-8 probeert maximale compatibiliteit met ASCII mogelijk te maken. Het is 8-bit, maar biedt ruimte aan alle personages via een substitutiemechanisme en meerdere paren waarden per teken. UTF-16-greppels perfecte ASCII-compatibiliteit voor een completere 16-bits compatibiliteit met de standaard.
- ISO-10646 - Dit is geen echte codering, alleen een tekenset van Unicode die is gestandaardiseerd door de ISO. Het is vooral belangrijk omdat het het karakterrepertoire is dat door HTML wordt gebruikt. Sommige van de geavanceerdere functies die door Unicode worden aangeboden en waarmee collatie en rechts naar links naast links-naar-rechts scripting mogelijk zijn, ontbreken. Toch werkt het heel goed voor gebruik op het internet, omdat het een breed scala aan scripts mogelijk maakt en de browser de glyphs kan interpreteren. Dit maakt de lokalisatie enigszins eenvoudiger.
Welke codering moet ik gebruiken?
Welnu, ASCII werkt voor de meeste Engelssprekenden, maar niet voor veel meer. Vaker zie je ISO-8859-1, dat werkt voor de meeste West-Europese talen. De andere versies van ISO-8859 werken voor Cyrillische, Arabische, Griekse of andere specifieke scripts. Als u echter meerdere scripts in hetzelfde document of op dezelfde webpagina wilt weergeven, biedt UTF-8 een veel betere compatibiliteit. Het werkt ook heel goed voor mensen die de juiste interpunctie, wiskundesymbolen of tekens uit de losse poling gebruiken, zoals vierkanten en selectievakjes.

(Meerdere talen in één document, Screenshot van gujaratsamachar.com)
Er zijn nadelen van elke set echter. ASCII is gelimiteerd in leestekens, dus het werkt niet ongelooflijk goed voor typografisch correcte bewerkingen. Hebt u ooit van Word gekopieerd en geplakt om een rare combinatie van glyphs te hebben? Dat is het nadeel van ISO-8859, of beter gezegd, de veronderstelde interoperabiliteit met OS-specifieke codepagina's (we kijken naar JOU, Microsoft!). Het grootste nadeel van UTF-8 is het ontbreken van de juiste ondersteuning bij het bewerken en publiceren van applicaties. Een ander probleem is dat browsers vaak het bytevolgordeteken van een UTF-8-gecodeerd teken niet interpreteren en weergeven. Dit resulteert in het weergeven van ongewenste glyphs. En natuurlijk maakt het declareren van een codering en het gebruiken van tekens van een andere zonder ze correct te declareren / ernaar te verwijzen op een webpagina, het voor browsers moeilijk om ze correct weer te geven en voor zoekmachines om ze op de juiste manier te indexeren.
Voor uw eigen documenten, manuscripten, enzovoort, kunt u alles gebruiken wat u nodig hebt om de klus te klaren. Wat het web betreft, lijkt het er echter op dat de meeste mensen het erover eens zijn om een UTF-8-versie te gebruiken die geen byte-opdrachtteken gebruikt, maar dat is niet helemaal unaniem. Zoals je ziet, heeft elke karaktercodering zijn eigen gebruik, context en sterke en zwakke punten. Als eindgebruiker zult u waarschijnlijk hier niet mee te maken krijgen, maar nu kunt u de extra stap voorwaarts maken als u daarvoor kiest.

Google heeft zijn hoofd gegooid in de router en smarthome ring in één keer met de introductie van hun OnHub-router, een router die de gemakkelijkste en meest probleemloze routerervaring belooft die je ooit hebt gehad met een supereenvoudige installatie, automatische beveiligingsupdates, smarthome-integratie en meer.

Hoe uzelf te beschermen tegen Ransomware (zoals CryptoLocker ea)
Ransomware is een type malware dat probeert geld van u af te persen. Er zijn veel varianten, te beginnen met CryptoLocker, CryptoWall, TeslaWall en vele anderen. Ze houden uw bestanden gegijzeld en houden ze vast voor honderden dollars. De meeste malware wordt niet meer gemaakt door verveelde tieners die chaos willen veroorzaken.



